
Introducing Helical's Virtual Lab for target discovery
How Helical built an in-silico lab for translational target discovery and validated it across 11+ indications and four therapeutic areas, including work independently run and assessed by pharmaceutical partners.

Recovering Known Targets at Scale
Across 11+ indications in neurology, cardiology, oncology, and immunology, our Virtual Lab recovers known disease-relevant targets at up to 43% hit rate (ie, 43 of the top-100 prioritized targets are known with prior biological or experimental support). It outperforms both differential expression (DESeq2) and random baselines on every indication tested, across independent pharma collaborations.
Platform-level consistency across therapeutic areas is the real test. A framework can look compelling on a hand-picked indication. The question is whether it continues to surface disease-relevant biology when applied across independent diseases. That cross-context performance is what gives confidence not just in the known targets recovered (our "calibration test"), but in the novel targets and pathways prioritized beyond the known set. This doesn't prove every novel prediction is correct, but systematic enrichment across diverse indications is the prerequisite for taking novel predictions seriously. Several of those novel candidates are now advancing into wet-lab follow-up with our pharma partners.
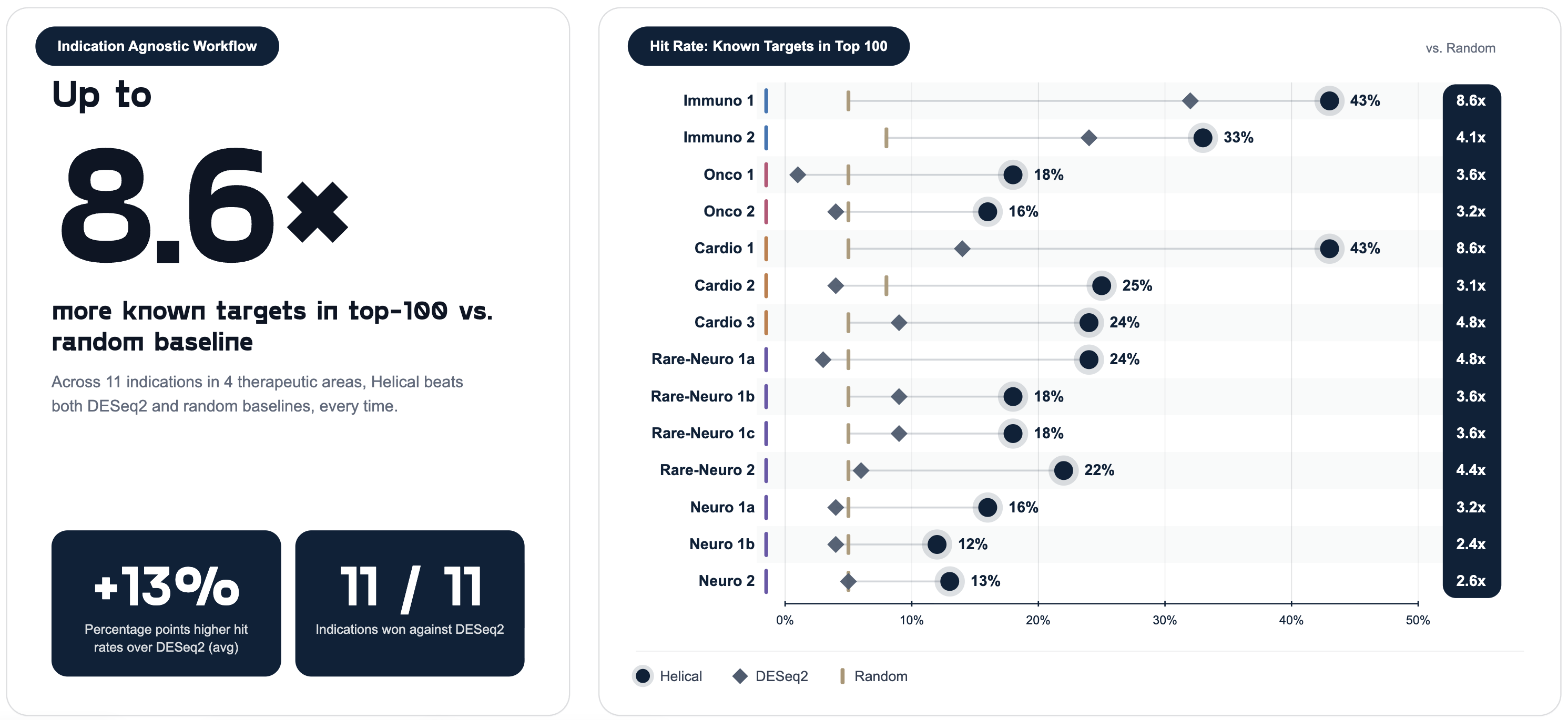

Figure 1. Hit rate (percentage of known disease-relevant targets recovered in the top 100 ranked candidates) for Helical (navy), DE-seq2 (graphite), and random (sand) across 11+ indications in neurology, cardiology, oncology, and immunology. Peak: 8.6x over random. Median: 4x. Exceeds both baselines on every indication. Known targets sourced from OpenTargets, DEPMAP, and CRISPRi screens.
From Association to Restoration: What Target ID Has Been Missing
So how does this work, and why does it matter?
Target identification is one of the highest-leverage decisions in drug discovery. The right target can shape the trajectory of an entire program. The wrong one can cost years of work and substantial experimental investment.
Most approaches today remain largely observational. They rank targets based on what is associated with disease: differential expression, genetic association, static pathway evidence. All of these signals can tell you what is altered in disease, but none directly tell you what is most likely to restore a healthy phenotype. Bio foundation models (BioFMs) have since brought far richer representations of disease biology, but most workflows still apply them to the same question.
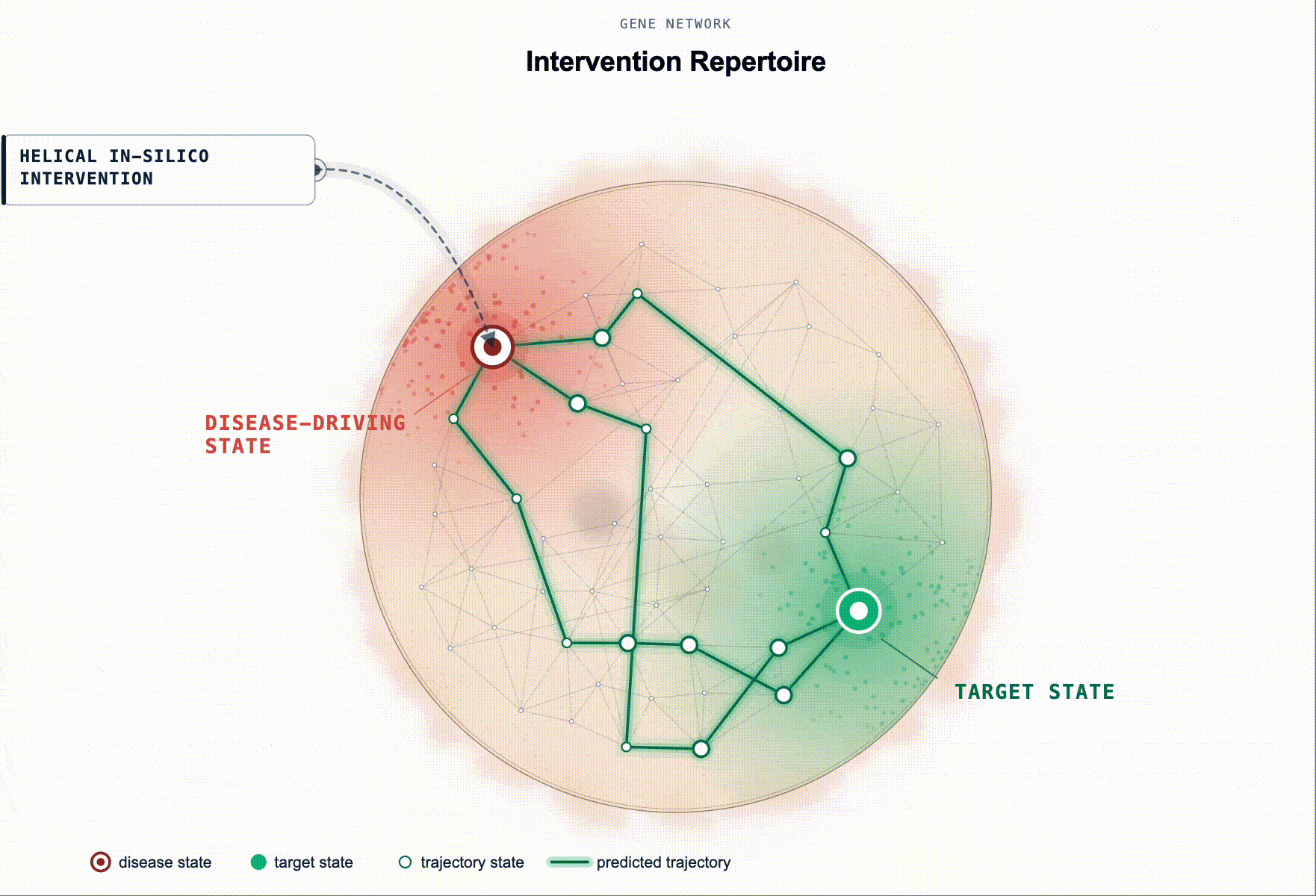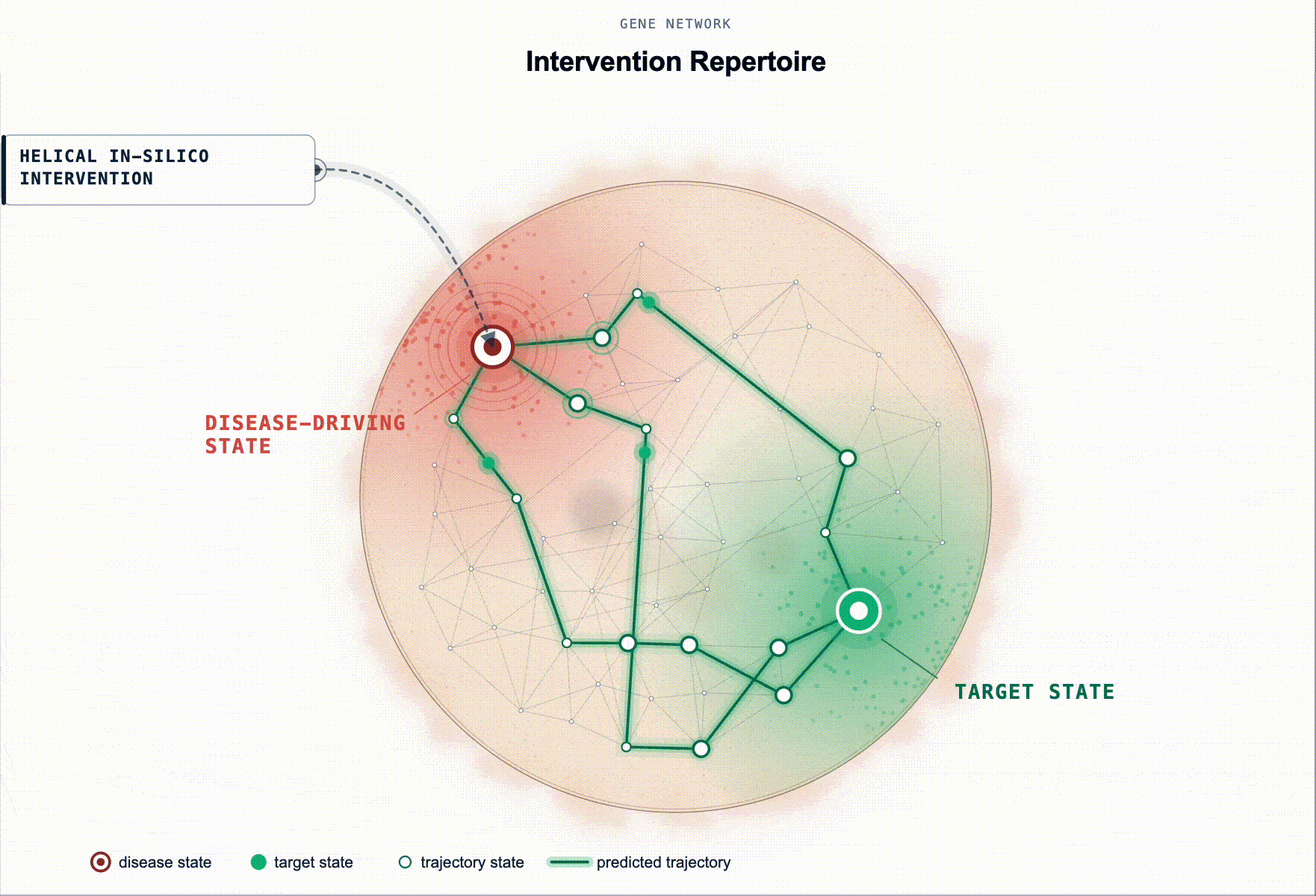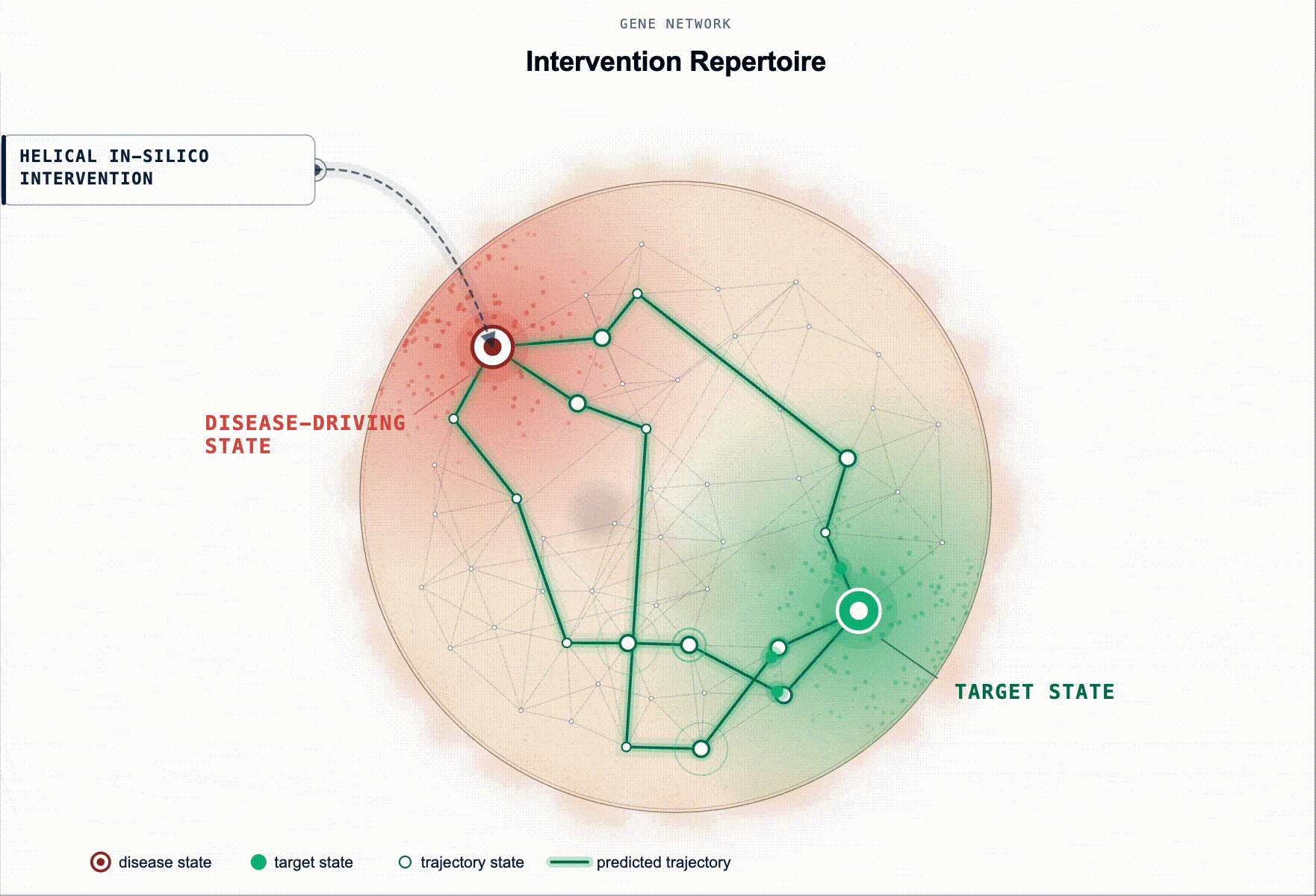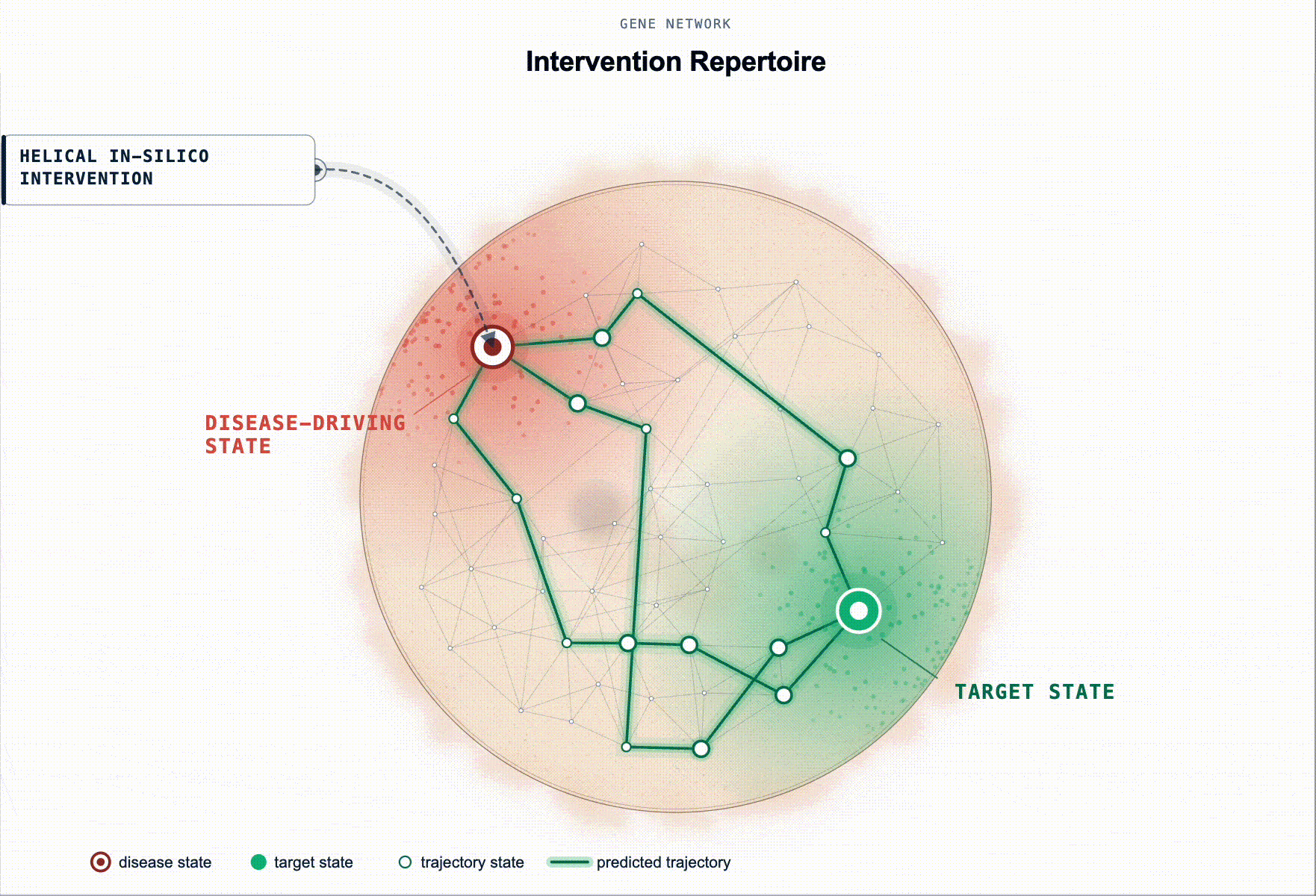
What has been missing is not more association evidence but an executable disease model. Something a scientist can intervene on in-silico and ask: "if I knock these genes down in this cell state, does the system restore?"
That is the question drug discovery must answer. Association evidence is essential, but insufficient to justify intervention.
Rather than ranking by association, our framework prioritises targets by their predicted capacity to restore healthy state. Starting from a disease-tailored BioFM, we systematically perturb genes in-silico and rank them according to whether the perturbation shifts the modelled disease-driving cell state back toward health. For multi-cellular disease, this principle extends to reshaping the disease-driving communication program between cell populations.
This turns target ID from association ranking into in-silico hypothesis testing: which perturbations are most likely to produce a meaningful restorative effect, in which cell types, and under which disease contexts.
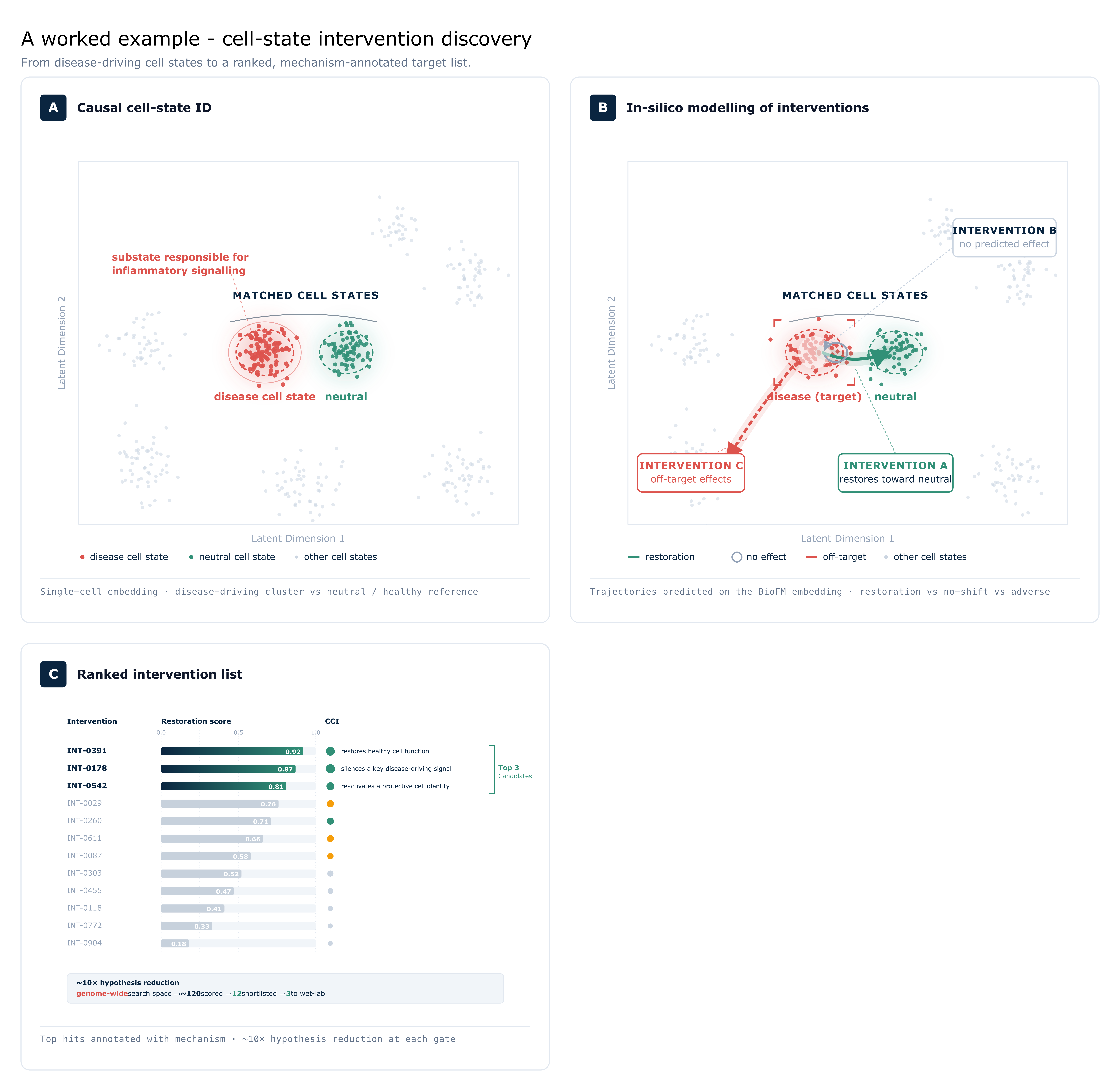
Figure 2. Identification of disease-associated cell states and ranked gene targets for restoring healthy cell states. (a) Disease-associated cell state identification. Cell states exhibiting aberrant signaling in disease relative to a healthy baseline are identified for downstream in silico perturbation analysis. (b) Genes are scored by their predicted ability to shift disease-associated cell states toward healthy reference states (restoration). This is illustrated as disease and healthy cell-state distributions in a BioFM reduced embedding space, with arrows indicating the direction of perturbation-induced state transitions.(c) Targets are ranked according to their restorative effects.
Biology First: The Right Model and the Right Workflow for the Disease (Model Factory)
Making this work across indications requires more than a good model. It requires a system that adapts to each disease context.
A core lesson from building the Virtual Lab is that there is rarely a single universal winner in biology. The most hyped model is often not the one that performs best for a specific disease setting. And even with the right model, the same workflow cannot simply be applied everywhere.
That is why we built a Model Factory: a systematic framework to tailor, benchmark, and select models against disease biology rather than defaulting to whichever foundation model is currently most talked about. Models alone do not make discoveries. The system built around them, how they are selected, adapted, and matched to the biology, is what makes their outputs meaningful. The Model Factory is that system.
Just as importantly, the downstream workflow adapts to the mechanism of disease. We have different targeting angles depending on the pathology and the biology driving it. Figure 3 illustrates this process: we first benchmark candidate foundation models against disease-relevant evaluation axes, select the strongest performer, and then systematically evaluate training adaptations of that model to identify the configuration best suited to the biology at hand.
In some settings, the key problem is cell-intrinsic disease biology, where in-silico perturbation of cellular state is the right abstraction. Here, we ask which perturbations restore dysfunctional cells toward healthier reference states.
Where pathology is driven by cell-cell interaction (CCI), single-cell state alone cannot capture the relevant biology. In inflammatory conditions like psoriasis, rheumatoid arthritis, and IBD, for instance, Th17 cells are central drivers, but their disease role plays out through communication with other immune and tissue-resident populations. Ranking targets within one cell type would miss the intercellular program that actually sustains disease. That is why we use CCI-adapted models and workflows that explicitly model intercellular signalling programs and ask how perturbations reshape disease-driving interactions across cell types.
Other settings call for different framing entirely: isoform-level resolution where splice variants drive distinct disease biology that gene-level analysis would conflate, spatial context where tissue architecture shapes pathology in ways dissociation-based data cannot preserve, or perturbation-experiment priors where existing screens and genetic studies provide direct causal evidence that should anchor in-silico post perturbation effects predictions.
Biology has to come first. The model, the benchmark, and the workflow all need to be fit for purpose. That is how target ID generalises: not by forcing every disease through the same pipeline, but by matching the model and workflow to the biology actually driving pathology.
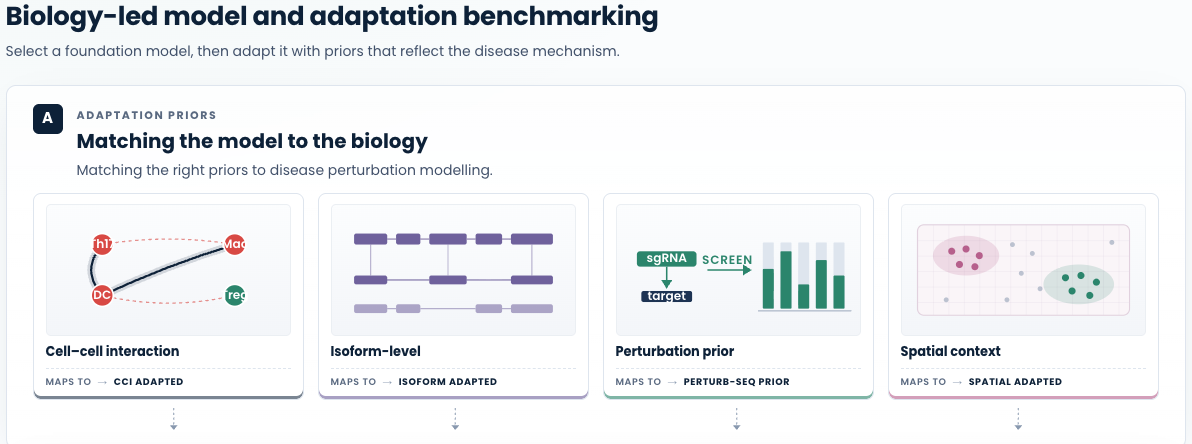

Figure 3. Systematic model and adaptation benchmarking guided by biological relevance. Our workflow adapts to the mechanism of disease: we benchmark candidate foundation models on disease-relevant axes, select the strongest base, and then evaluate training adaptations of that model guided by priors that reflect how the disease manifests. (A) We illustrate with four adaptation priors as examples, cell–cell interaction, isoform-level resolution, perturbation evidence, and spatial context, each match a class of disease biology and feed an adapted variant of the selected foundation model into Stage 2 of the benchmark below. Different disease mechanisms call for different priors; each mode is a biology-led adaptation, not an arbitrary hyperparameter sweep. (B) Bubble chart of metric performance across five evaluation axes. Bubble size and colour intensity encode within-column rank (larger and darker = better). The dashed line separates two stages. Stage 1 : base model selection: candidate foundation models are compared on disease-relevant axes; the pre-trained model B is selected (highlighted row). Stage 2 : model personalisation: training adaptations of the selected model B are evaluated, with the four biology-led adaptations bolded and the chosen CCI adapted variant highlighted for consistently strong performance across disease-relevant axes.
What Helical's Virtual Lab Unlocks
Target ID is one instantiation of a more general framework. The same in-silico lab, the same model factory, the same expertly crafted toolkits and workflow rubrics, unlocks a broader set of capabilities:
- Target identification: systematic in-silico perturbation and validation to identify targets that reshape disease-driving cell states and intercellular programs.
- Cell-state discovery: identifying disease-driving cell states that should be modeled, perturbed, or validated.
- Patient stratification: identifying patient subgroups that share disease-driving biology and are therefore more likely to respond to a given intervention.
- Genomic integration: linking sequence variation to predicted effects on isoforms, regulation, and disease biology.
- Multi-omics modeling: integrating the most relevant molecular and tissue-level modalities , including single-cell, bulk, spatial, genomic, proteomic, and clinical data , into a shared disease model.
- Therapeutic design: supporting antisense oligonucleotide (ASO) design and modeling before experimental screening.
These workflows define how disease state is represented, how perturbations are simulated, how restorative effects are quantified, and how outputs are turned into prioritisation decisions. The value is not just in representation learning. It is in translating model outputs into decision-ready hypotheses that are mechanistically grounded, disease-contextualised, and ready for experimental follow-up. This is where most of the field still falls short.
Figure 4. The Virtual Lab at a glance. The scientist orchestrates a three-stage workflow: data ingestion, the Model Factory (where BioFMs are tailored and benchmarked against disease biology), and the Virtual Lab (for in silico exploration and validation). At each stage, scientists contribute experimental design, iterative feedback, and domain-specific priors (e.g., CCI axes, disease context, spatial information). The framework supports multiple downstream use cases, including target identification (illustrated as an abstracted hit-rate curve), cell-state discovery, patient stratification, genomic integration, multi-omics modeling, and therapeutic design.
What's Next
A scientific manuscript with multiple pharma partners is forthcoming, detailing the framework, benchmarks, and case studies. We are grateful for these collaborations, and more are coming.
Wet-lab validation of platform-derived candidates is underway. We are also expanding the in-silico lab across additional therapeutic areas and deeper multi-omic integration. We look forward to sharing more as partner programs and validation studies progress.
If you are working on translational target ID, or any of the capabilities above, and this resonates, get in touch.
Get started
About Helical
Helical is the virtual AI lab for pharma. We are the application layer that orchestrates the world's best bio foundation models, aligned to your biology, so pharma and biotech teams can run scalable, reproducible in-silico experiments across target discovery, biomarker development, patient stratification, and RNA therapy design.
To learn more or schedule an intro call, reach out to hayden@helical.bio or book a time here








